
Function (mathematics)
| Function |
|---|
| x ↦ f (x) |
| History of the function concept |
| Examples of domains and codomains |
| Classes/properties |
| Constructions |
| Generalizations |








수학(mathematics)에서, 함수(function)[note 1]는 첫 번째 집합의 모든 각 원소를 두 번째 집합의 정확하게 한 원소와 연결하는 집합(sets) 사이의 관계(relation)입니다. 전형적인 예제는 정수(integer)에서 정수로의 또는 실수(real number)에서 실수로의 함수입니다.
함수는 원래 어떤 양이 다른 양에 의해 어떻게 변하는지를 이상화한 것입니다. 예를 들어, 행성(planet)의 위치는 시간의 함수입니다. 역사적으로(Historically), 그 개념은 17세기 말 무한소 미적분학(infinitesimal calculus)과 함께 정교해졌고, 19세기까지, 고려되는 함수는 미분-가능(differentiable)이었습니다 (즉, 그들은 정칙성(regularity)의 높은 차수를 가졌습니다). 함수의 개념은 집합 이론(set theory)의 관점에서 19세기의 끝에서 공식화되었었고, 이것은 개념의 적용 영역을 대단히 확장했었습니다.
함수는 집합(set) X, 함수의 도메인(domain)의 각 원소 x를 또 다른 집합 Y (같은 집합이 가능함), 함수의 코도메인(codomain)의 단일 원소 y에 연결시키는 진행 또는 관계입니다. 만약 함수가 f로 불리우면, 이 관계는 y = f (x) (이것은 f of x로 크게 읽습니다)로 표시되고, 원소 x는 함수의 인수(argument) 또는 입력이며, y는 함수의 값, 출력, 또는 f에 의한 x의 이미지입니다.[1] 입력을 나타내는 것에 사용되는 기호는 함수의 변수(variable)입니다 (우리는 f는 변수 x의 함수라고 종종 말합니다).
함수는, 그것의 그래프(graph)로 불리는, 모든 쌍(pairs) (x, f (x))의 집합에 의해 고유하게 나타냅니다.[note 2] 도메인과 코도메인이 실수의 집합일 때, 그러한 쌍의 각각은 평면에서 점의 데카르트 좌표(Cartesian coordinates)로 여길 수 있습니다. 이들 점의 집합은 함수의 그래프로 불립니다; 그것은 함수를 묘샤하는 인기있는 수단입니다.
함수는 과학(science) 및 수학의 대부분 분야에서 널리 사용됩니다. 함수는 수학의 대부분 분야에서 "조사의 중심적 대상"이라고 말해져 왔습니다.[2]



Definition


직관적으로, 함수는 집합 X의 각 원소를 집합 Y의 하나의 원소와 연관시키는 진행입니다.
공식적으로, 집합 X로부터 집합 Y로의 함수 f는 x ∈ X, y ∈ Y를 만족하는 순서쌍 (x, y)의 집합 G에 의해 정의되고, X의 모든 각 원소는 G에서 정확하게 하나의 순서쌍의 첫 번째 성분입니다.[3][note 3] 달리 말해서, X에서 모든 각 x에 대해, 순서쌍 (x, y)는 함수 f를 정의하는 쌍의 집합에 속하는 것을 만족하는 정확히 하나의 원소 y가 있습니다. 집합 G는 함수의 그래프(graph of the function)로 불립니다. 공식적으로 말해서, 그것은 함수로 식별될 수 있지만, 이것은 함수의 보통의 해석을 진행으로 숨깁니다. 그러므로, 공통적인 사용법에서, 함수는 일반적으로 그의 그래프와 구별됩니다. 비록 일부 저자는 "맵"과 "함수"를 구분할지라도 (#Map을 참조하십시오), 함수는 맵(maps) 또는 맵핑(mappings)으로 역시 불립니다.
함수의 정의에서, X와 Y는 각각 함수 f의 도메인(domain)과 코도메인(codomain)으로 불립니다. 만약 (x, y)가 f를 정의하는 집합에 속하면, y는 f 아래 x의 이미지(image), 또는 인수(argument) x에 적용된 f의 값(value)입니다. 특히 숫자의 문맥에서, 우리는 y는 그의 변수의 값 x에 대해 f의 값, 또는, 더 짧게, y는 x의 f의 값으로 역시 말하며, y = f(x)로 나타냅니다.
두 함수 f와 g는, 만약 도메인과 코도메인 집합이 같고 그들의 출력값이 전체 도메인에서 일치하면, 같습니다. 공식적으로, f = g는 모든 x ∈ X에 대해 f(x) = g(x)이며, 여기서 f:X → Y 및 g:X → Y입니다.[4][5][note 4]
도메인과 코도메인은 함수가 정의될 때 항상 명시적으로 주어지는 것은 아니고, 어떤 (아마도 어려운) 계산없이, 우리는 단지 도메인이 더 큰 집합에 포함되어 있다는 것을 알고 있습니다. 전형적으로, 이것은 수학적 해석학(mathematical analysis)에서 발생하며, 여기서 "X에서 Y로의 함수"는 흔히 도메인으로 X의 적절한 부분집합(proper subset)을 가질 수 있는 함수를 참조합니다. 예를 들어, 실수에서 실수로의 함수는 실수 변수(real variable)의 실수-값(real-valued) 함수를 나타나고, 이 구문은 함수의 도메인이 실수 전체 집합임을 의미하는 것이 아니라, 단지 도메인은 비-빈 열린 구간(open interval)을 포함하는 실수의 하나의 집합임을 의미합니다; 그러한 함수는 그런-다음 부분 함수(partial function)로 불립니다. 예를 들어, 만약 f가 도메인과 코도메인으로 실수를 갖는 함수이면, 값 x를 값 로 매핑하는 하나의 함수는 실수에서 실수로의 함수 g이며, 그의 도메인은, f(x) ≠ 0를 만족하는, 실수 x의 집합입니다.

함수의 치역(range)은 도메인에서 모든 원소에 대한 이미지의 집합입니다. 어쨌든, 치역(range)은, 일반적으로 오래된 교과서에서, 코도메인의 동의어로 때때로 사용됩니다.[citation needed]
Relational approach
두 집합 와 의 데카르트 곱의 임의의 부분집합은 이들 두 집합 사이에 이항 관계(binary relation) 를 정의합니다. 임의의 관계는 위에서 주어진 함수에 대해 필요한 조건을 위반하는 쌍을 포함할 수 있음은 직접적입니다.


함수형 관계(functional relation 또는 univalent)는, 에서 모든 및 에서 에 대해, 다음을 만족하는 관계입니다:



함수형 관계는 그의 도메인이 X의 부분집합인 코도메인 를 갖는 함수로 식별될 수 있습니다.
전체 관계(total relation)는 다음을 만족하는 관계입니다:

공식적으로, 함수는 함수형 및 전체 둘 다인 관계로 식별될 수 있습니다. 전체가 아닌 함수형 관계는 부분 함수(partial function)로 불립니다.
함수와 함수 합성의 다양한 속성은 관계의 언어에서 재공식화될 수 있습니다. 예를 들어, 함수는 만약 전환 관계(converse relation) 가 함수형이면, 단사적(injective)이며, 여기서 반대 관계는 로 정의됩니다.[6]


As an element of a Cartesian product over a domain
어떤 주어진 도메인에서 코도메인으로의 모든 함수의 집합은 도메인에 의해 인덱스된(indexed) 코도메인의 사본의 데카르트 곱으로 때때로 식별됩니다. 즉, 및 가 주어지면, 임의의 함수 는 인덱스 집합 에 걸쳐 의 사본의 데카르트 곱의 원소입니다:


좌표를 갖는 튜플로 를 보면, 각 에 대해, 이 튜플의 번째 좌표는 값 입니다. 이것은 각 에 대해, 함수가 어떤 원소 , 즉 를 선택한다는 직관을 반영합니다. (이 관점은 예를 들어 선택 함수(choice function)의 논의에서 사용됩니다.)





무한 데카르트 곱은 함수의 집합으로 종종 단순히 "정의"됩니다.[7]
Notation
함수를 나타내는 다양한 표준 방법이 있습니다. 가장 공통적으로 사용되는 표기법은 함수형 표기법이며, 이것은 명시적으로 함수 및 인수의 이름을 제공하는 방정식을 사용하여 함수를 정의합니다. 이것은 미묘한 점을 발생시키며, 종종 함수의 기본 처리에서 말을 둘러댑니다: 함수는 그들의 값과 구별됩니다. 따라서, 함수 f는 그의 도메인의 값 x0에서 그의 값 f(x0)와 구별되어야 합니다. 어느 정도까지는, 심지어 실제로 일을 하는 수학자도 비공식적인 환경에서 편리함, 및 현학적 언어 사용을 피하기 위해 둘을 융합할 것입니다. 어쨌든, 엄격하게 말해서, "를 함수 f(x) = x2로 놓습니다"라고 쓰는 것은 표기법의 남용(abuse of notation)인데, 왜냐하면 f(x) 및 x2은 함수 자체라기보다는 x에서 f의 값으로 둘 다 이해되어야 합니다. 대신에, 비록 장황할지라도, "를 x의 모든 실수 값에 대해 유효한 방정식 f(x) = x2에 의해 정의되는 함수로 놓습니다"라고 쓰는 것이 정확합니다. 간결한 문구는 "f(x) = x2를 갖는 로 놓으며" 여기서 "함수라는" 불필요한 것은 생략되고, 관례에 의해, "의 도메인에서 모든 에 대해"로 이해됩니다.

언어와 표기법에서 이 구별은 함수 자체가 다른 함수에 대해 입력으로 사용되는 경우에서 중요하게 됩니다. (또 다른 함수를 입력으로 취하는 함수는 함수형(functional)으로 이름-짓습니다.) 아래에 설명된, 함수를 나타내는 다른 접근은, 이 문제를 피하지만 덜 공통적으로 사용됩니다.
Functional notation
1734년 레온하르트 오일러(Leonhard Euler)에 의해 처음 사용되었을 때,[8] 함수는 일반적으로 이탤릭 글꼴(italic font)에서 하나의 문자, 대부분 소문자 f, g, h로 구성되는 기호에 의해 표시됩니다. 일부 널리 사용된 함수는 여러 문자 (보통 둘 또는 셋, 일반적으로 그들 이름의 약어)로 구성된 기호에 의해 표시됩니다. 관례에 의해, 이들 경우에서, 로마자 형식(roman type)이, 하나의-문자 기호의 이탤릭 글꼴과 달리, 사인 함수(sine function)에 대해 "sin"과 같은, 사용됩니다.
표기법 (읽기: y equals f of x)

는 쌍 (x, y)가 함수 f를 정의하는 쌍들의 집합에 속함을 의미합니다. 만약 X가 f의 도메인이면, 함수를 정의하는 순서쌍 집합은, 따라서, 집합-구성 표기법(set-builder notation)을 사용하여 다음입니다:

종종, 함수의 정의는 f가 명시적 인수 x와 무슨 관계가 있는지에 의해 제공됩니다. 예를 들어, 함수 f는 모든 실수 x에 대해 다음 방정식에 의해 정의될 수 있습니다:
- .

이 예제에서, f는 여러 더 간단한 함수:제곱, 더하기 1, 및 사인을 취하는 것의 합성(composite)으로 생각될 수 있습니다. 어쨌든, 단지 사인 함수는 공통적인 명백한 기호 (sin)를 가지지만, 반면에 제곱과 그런-다음 더하기 1의 조합은 다항식 표현 에 의해 설명됩니다. 새로운 함수 이름을 도입없이 제곱 또는 더하기 1과 같은 함수를 명시적으로 참조하기 위해 (예를 들어, 및 에 의해 함수 g와 h를 정의하는 것), 아래 방법 (화살표 표기법 또는 점 표기법) 중 하나가 사용될 수 있습니다.



때때로 함수형 표기법의 괄호는 함수를 나타내는 기호가 여러 문자로 구성되고 모호성이 발생하지 않을 때 생략됩니다. 예를 들어 는 대신에 쓸 수 있습니다.


Arrow notation
함수 f의 도메인 X와 코도메인 Y를 명시적으로 표현하기 위해, 화살표 표기법이 종종 사용됩니다 (읽기: "the function f from X to Y" 또는 "the function f mapping elements of X to elements of Y"):
또는

이것은 원소에 대해 화살표 표기법을 갖는 관계에서 종종 사용됩니다 (읽기: "f maps x to f (x)"), 함수 기호, 도메인, 및 코도메인을 제공하는 화살표 표기법 바로 아래에 종종 쌓입니다:

예를 들어, 만약 곱셈이 집합 X 위에 정의되면, X 위의 제곱 함수(square function) 는 다음에 의해 모호하지-않게 정의됩니다 (읽기: "the function from X to X that maps x to x ⋅ x")


후자의 줄은 더 공통적으로 다음으로 쓰입니다:

종종, 함수 기호, 도메인 및 코도메인을 제공하는 표현은 생략됩니다. 따라서, 화살표 표기법은, 종종 그렇듯이, 그의 인수의 관점에서 함수의 값을 표현하는 공식에 의해 정의되는 함수에 대해 기호를 도입하는 것을 피하는 것에 유용합니다. 화살표 표기법의 공통적인 응용일 때, 가 두-인수 함수로 가정하고, 우리는 새로운 함수 이름 도입없이 두 번째 인수를 값 t0에 고정함으로써 생성된 부분적으로 적용된 함수(partially applied function) 로 참조하기를 원합니다. 문제에서 맵은 원소에 대해 화살표 표기법을 사용하여 로 표시될 수 있습니다. 표현 (읽기: "the map taking x to ")은 단지 하나의 인수를 갖는 이 새로운 함수를 나타내지만, 반면에 표현 은 점 에서 함수 f의 값을 참조합니다.






Index notation
인덱스 표기법은 함수형 표기법 대신에 종종 사용됩니다. 즉, f (x)를 쓰는 대신에, 우리는 를 씁니다.

이것은 전형적으로 그의 도메인이 자연수(natural number)의 집합인 함수에 대해 경우입니다. 그러한 함수는 수열(sequence)로 불리고, 이 경우에서 원소 은 수열의 n번째 원소로 불립니다.

인덱스 표기법은 "참 변수(true variables)"와 매개-변수(parameter)로 불리는 일부 변수를 구별하기 위해 역시 종종 사용됩니다. 사실, 매개-변수는 문제의 연구 동안 고정되는 것으로 고려되는 특정 변수입니다. 예를 들어, 맵 (위를 참조하십시오)는, 만약 우리가 모든 에 대해 숙식 에 의해 맵 의 모음을 정의한다면, 인덱스 표기법을 사용하여 로 나타낼 것입니다.




Dot notation
표기법 에서, 기호 x는 임의의 값을 나타내지 않고, 그것은 단순히 자리 표시자(placeholder)를 의미하며, 만약 x가 화살표 왼쪽에 있는 임의의 값으로 대체되면, 그것은 화살표 오른쪽에 있는 같은 값으로 대체되어야 합니다. 그러므로, x는 임의의 기호, 종종 중간점(interpunct) " ⋅ "으로 대체될 수 있습니다. 이것은 함수 f (⋅)와 x에서 그의 값 f (x)를 구별하는 것에 유용할 수 있습니다.

예를 들어, 는 를 나타내는 것이고, 는 변수 위쪽 경계: 을 가진 적분에 의해 정의된 함수를 의미할 수 있습니다.




Specialized notations
수학의 하위-분야에서 함수에 대해 다른, 전문화된 표기법이 있습니다. 예를 들어, 선형 대수(linear algebra) 및 함수형 해석학(functional analysis)에서 선형 형식(linear form) 및 그들이 작용하는 벡터(vectors)는 놓여 있는 이중성(duality)을 보이기 위해 이중 쌍(dual pair)을 사용하여 표시됩니다. 이것은 양자 역학에서 브라–켓 표기법(bra–ket notation)의 사용과 유사합니다. 논리(logic) 및 계산 이론(theory of computation)에서, 람다 계산법(lambda calculus)의 함수 표기법은 함수 추상화(abstraction)와 응용(application)의 기본 개념을 명시적으로 표현하기 위해 사용됩니다. 카테고리 이론(category theory) 및 호몰로지 대수학(homological algebra)에서, 함수의 네트워크는 위에서 설명한 함수에 대해 화살표 표기법을 확장하고 일반화하는 교환-속성 다이어그램(commutative diagram)을 사용하여 함수와 그들의 합성이 서로 사이에 교환(commute)하는 방법의 관점에서 설명됩니다.
Other terms
| 용어 | "함수"와 차이 |
|---|---|
| 맵/매핑 | 없음; 용어는 동의어입니다.[9] |
| 맵은 그의 코도메인으로 임의의 집합을 가질 수 있지만, 일부 문맥에서, 전형적으로 오래전 책에서, 함수의 코도메인은 구체적으로 실수(real) 또는 복소수(complex)의 집합입니다.[10] | |
| 대안적으로, 맵은 (예를 들어, 그의 정의에서 구조화된 코도메인을 명시적으로 지정함으로써) 특별한 구조와 관련됩니다. 예를 들어 선형 맵(linear map).[11] | |
| 준동형 | 구조의 연산을 보존하는 같은 유형의 두 구조(structures) 사이의 함수 (예를 들어, 그룹 준동형(group homomorphism)).[12][13] |
| 사상 | 임의의 카테고리(category)에 대한, 심지어 카테고리의 대상이 집합이 아닐 때, 준동형의 일반화 (예를 들어, 그룹(group)이 단지 하나의 대상을 가진 카테고리를 정의하며, 이것은 사상으로 그룹의 원소를 가집니다; 이 예제와 다른 비슷한 것에 대해 Category (mathematics) § Examples를 참조하십시오).[14][12][15] |
Map
함수는 종종 맵(map) 또는 맵핑(mapping)으로 역시 불리지만, 일부 저자는 용어 "맵" 및 "함수" 사이의 구별을 만듭니다. 예를 들어, 용어 "맵"은 특수 구조의 일부 종류를 갖는 "함수"에 대해 종종 예약됩니다 (예를 들어, 매니폴드의 맵(maps of manifolds)); 특히 맵은 간결성을 위해 준동형의 자리에서 종종 사용됩니다 (예를 들어, 선형 맵(linear map) 또는 G에서 H로의 그룹 준동형(group homomorphism) 대신에 G에서 H로의 맵). 일부 저자는 코도메인 구조가 함수의 정의에 명시적으로 속하는 경우에 대해 단어 매핑을 예약합니다.[16]
서지 랭(Serge Lang)과 같은,[17] 일부 저자는 코도메인이 실수(real) 또는 복소수(complex)의 부분집합인 것에 대해 맵을 참조하기 위해 오직 "함수"를 사용하고, 용어 매핑은 보다 일반적인 함수에 대해 사용합니다.
동력학적 시스템(dynamical system)의 이론에서, 맵은 이산 동력학적 시스템(discrete dynamical systems)을 생성하기 위해 사용되는 진화 함수(evolution function)를 나타냅니다. 역시 푸앵카레 맵(Poincaré map)을 참조하십시오.
맵의 어떤 정의가 사용되던지, 도메인(domain), 코도메인(codomain), 단사(injective), 연속(continuous)과 같은 관련된 용어는 함수에 대해 같은 의미를 가집니다.
Specifying a function
함수 의 도메인의 각 원소 에 대한, 정의에 의해, 함수 가 주어지면, 그것과 관련된 고유한 원소, 에서 의 값 가 있습니다. 가 와 어떻게 관련되어 있는지 명시적 또는 암시적으로 둘 다를 지정 또는 기술하기 위한 여러 방법이 있습니다. 때때로, 정리 또는 공리(axiom)가 그것을 더 정확하게 설명하는 것없이 일부 속성을 가지는 함수의 존재를 주장합니다. 종종, 명세 또는 설명은 함수 의 정의로 참조됩니다.
By listing function values
유한 집합에서, 함수는 도메인의 원소와 관련되는 코모메인의 원소를 나열함으로써 정의될 수 있습니다. 예를 들어, 만약 이면, 우리는 함수 를 에 의해 정의할 수 있습니다.



By a formula
함수는 산술 연산(arithmetic operations) 및 이전에 정의된 함수의 조합을 설명하는 공식(formula)에 의해 종종 정의됩니다; 그러한 공식은 도메인의 임의의 원소의 값으로부터 함수의 값을 계산하는 것을 허용합니다. 예를 들어, 위의 예제에서, 는 에 대해 공식 에 의해 정의될 수 있습니다.


함수가 이 방법으로 정의될 때, 그 도메인의 결정이 때때로 어렵습니다. 만약 함수를 정의하는 공식이 나눗셈을 포함하면, 분모가 영인 것에 대해 변수의 값은 도메인에서 반드시 제외해야 합니다; 따라서, 복잡한 함수에 대해, 도메인의 결정은 보조 함수의 영들(zeros)의 계산을 거칩니다. 마찬가지로, 만약 제곱근(square root)이 에서 로의 함수의 정의에서 발생하면, 도메인은 제곱근의 인수가 비-음수인 것에 대해 변수의 값의 집합에 포함됩니다.
예를 들어, 가 그의 도메인이 인 함수 를 정의하는데, 왜냐하면 은 만약 x가 실수이면 항상 양수이기 때문입니다. 다른 한편으로, 는 그의 도메인이 구간 [–1, 1]으로 줄어드는 실수에서 실수로의 함수를 정의합니다. (오래된 텍스트에서, 그러한 도메인은 함수의 정의의 도메인(domain of definition)으로 불렸습니다.)



함수는 그것을 정의할 수 있는 공식의 본질에 따라 종종 분류됩니다:
- 이차 함수(quadratic function)는 로 쓸 수 있는 함수이며, 여기서 a, b, c는 상수(constants)입니다.
- 보다 일반적으로, 다항 함수(polynomial function)는 오직 덧셈, 뺄셈, 곱셈, 및 비-음의 정수에 대한 지수(exponentiation)를 포함하는 수식으로 정의될 수 있는 함수입니다. 예를 들어, 및 .
- 유리 함수(rational function)는, 나눗셈이 역시 허용되는, 및 와 같은 것입니다.
- 대수적 함수(algebraic function)는 n번째 근(nth roots) 및 다항식의 근이 역시 허용되는, 같은 것입니다.
- 초등 함수(elementary function)[note 5]는, 로그(logarithm) 및 지수 함수(exponential functions)를 허용하는 같은 것입니다.





Inverse and implicit functions
도메인 X와 코도메인 Y를 갖는 함수 는, 만약 Y 안의 모든 각 y에 대해, y = f(x)를 만족하는 Y 안의 하나 및 오직 하나의 원소 x가 있으면, 전단사(bijective)입니다. 이 경우에서, f의 역함수(inverse function)는 y = f(x)를 만족하는 를 원소 에 매핑하는 함수 입니다. 예를 들어, 자연 로그(natural logarithm)는 양의 실수에서 실수로의 전단사 함수입니다. 그것은 이들 역함수를 가지며, 실수에서 양수 위로 매핑하는 지수 함수(exponential function)로 불립니다.

만약 함수 가 전단사가 아니면, 그것은 우리가 E에 대한 f의 제한(restriction)이 E에서 F로의 전단사이고, 따라서 역함수를 가지는 것을 만족하는 부분-집합 및 를 선택할 수 있는 것에서 발생할 수 있습니다. 역 삼각 함수(inverse trigonometric functions)는 이런 방법으로 정의됩니다. 예를 들어, 코사인 함수(cosine function)는 구간(interval) [0, π]에서 구간 [–1, 1] 위로의 전단사를, 제한에 의해, 유도하고, 아크코사인(arccosine)으로 불리는, 그의 역 함수는 [–1, 1]를 [0, π] 위로 매핑합니다. 다른 역 삼각 함수는 비슷하게 정의됩니다.


보다 일반적으로, 두 집합 X와 Y 사이의 이항 관계(binary relation) R이 주어지면, E를 모든 각 에 대해 x R y를 만족하는 어떤 가 있음을 만족하는 X의 부분집합으로 놓습니다. 만약 우리가 모든 각 에 대해 그러한 y를 선택함을 허용하는 기준을 가지면, 이것은 암시적 함수(implicit function)로 불리는 함수 를 정의하는데, 왜냐하면 그것은 관계 R에 의해 암시적으로 정의되기 때문입니다.


예를 들어, 단위 원(unit circle) 의 방정식은 실수 위에 관계를 정의합니다. 만약 –1 < x < 1이면 y의 두 가능한 값이 있으며, 하나는 양이고 다른 하나는 음입니다. x = ± 1에 대해, 이들 두 값은 둘 다 0과 같아집니다. 그렇지 않으면, y의 가능한 값이 없습니다. 이것은 그 방정식이 도메인 [–1, 1] 및 각각의 코도메인 [0, +∞)과 (–∞, 0]을 갖는 두 암시적 함수를 정의함을 의미합니다.

이 예제에서, 방정식은 y에 대해 풀 수 있으며, 을 제공하지만, 보다 복잡한 예제에서, 이것은 불가능합니다. 예를 들어, 관계 는 초제곱근(ultraradical)으로 불리는 x의 암시적 함수로 y를 정의하며, 이것은 도메인과 치역으로 을 가집니다. 초제곱근은 네 개의 산술 연산과 n번째 제곱근(nth roots)의 관점에서 절대 표현될 수 없습니다.


암시적 함수 정리(implicit function theorem)는 하나의 점의 이웃에서 암시적 함수의 존재와 유일성에 대해 온화한 미분-가능성(differentiability) 조건을 제공합니다.
Using differential calculus
많은 함수는 또 다른 함수의 역도함수(antiderivative)로 정의될 수 있습니다. 이것은 자연 로그(natural logarithm)의 경우이며, 이것은 1/x의 역도함수이며 x = 1에 대해 0입니다. 또 다른 공통적인 예제는 오차 함수(error function)입니다.
보다 일반적으로, 대부분의 특수 함수(special function)를 포함하는, 많은 함수들은 미분 방정식(differential equation)의 해로 정의될 수 있습니다. 가장 간단한 예제는 아마도 지수 함수(exponential function)이며, 이것은 그의 도함수와 같은 유일한 함수로 정의될 수 있고 x = 0에 대해 값 1을 취합니다.
거듭제곱 급수(power series)는 그들이 수렴하는 도메인 위에 함수를 정의하기 위해서 사용될 수 있습니다. 예를 들어, 지수 함수(exponential function)는 에 의해 제공됩니다. 어쨌든, 급수의 계수는 매우 임의적이므로, 수렴하는 급수의 합인 함수는 일반적으로 다르게 정의되고, 계수의 수열은 또 다른 정의를 기반으로 한 어떤 계산의 결과의 합입니다. 그런-다음, 거듭제곱 급수는 함수의 도메인을 확대하기 위해 사용될 수 있습니다. 전형적으로, 만약 실수 변수에 대해 함수가 어떤 구간에서 그의 테일러 급수(Taylor series)의 합이면, 이 거듭제곱 급수는, 도메인을 복소수(complex number)의 부분-집합, 급수의 수렴의 디스크(disc of convergence)로 즉시 확대하는 것을 허용합니다. 그런-다음 해석적 연속성(analytic continuation)은 거의 모든 전체의 복소 평면(complex plane)을 포함하는 것에 대해 도메인을 더 확대하는 것을 허용합니다. 이 진행은 로그(logarithm), 지수(exponential) 및 복소수의 삼각 함수(trigonometric functions)를 정의하는 것에 대해 일반적으로 사용되는 방법입니다.

By recurrence
수열(sequence)로 알려진, 그의 도메인이 비-음의 정수인 함수는, 재귀 관계(recurrence relation)에 의해 종종 정의됩니다.
비-음의 정수에 대한 팩토리얼(factorial) 함수 ()는 기본 예제인데, 왜냐하면 그것은 다음과 같은 재귀 관계와 초기 값 에 의해 정의될 수 있기 때문입니다:


- .

Representing a function
그래프(graph)는 함수의 직관적인 그림을 제공하기 위해 공통적으로 사용됩니다. 그래프가 함수를 이해하는 것에 어떻게 도움이 되는지 예제로서, 함수가 증가하는지 또는 감소하는지 여부를 그의 그래프로부터 쉽게 알 수 있습니다. 일부 함수는 막대 차트(bar chart)에 의해 역시 나타낼 수 있습니다.
Graphs and plots


함수 가 주어지면, 그의 그래프는, 공식적으로, 다음 집합입니다:

X와 Y가 실수(real number)의 부분-집합 (또는, 그러한 부분-집합, 예를 들어, 구간(intervals)으로 식별될 수 있는) 빈번한 경우에서, 원소 는 이-차원 좌표 시스템, 예를 들어 데카르트 평면(Cartesian plane)에서 좌표 x, y를 가지는 점으로 식별될 수 있습니다. 이것의 부분은 함수 (의 일부)를 나타내는 그림(plot)을 생성할 수 있습니다. 그림의 사용은 매우 유비쿼터스이므로 그들은 함수의 그래프라고 역시 불립니다. 함수의 그래픽적 표현은 다른 좌표 시스템에서 역시 가능합니다. 예를 들어, 에 대해 좌표 를 갖는 모든 점으로 구성되는, 제곱 함수(square function)




의 그래프는 데카르트 좌표 시스템에서 묘사될 때, 잘 알려진 포물선(parabola)을 산출합니다. 만약 숫자의 쌍으로 구성되는, 같은 공식적인 그래프를 갖는, 같은 이차 함수 는 극 좌표(polar coordinates) 에서 대신 그려질 수 있고, 획득된 그림은 페르마의 나선(Fermat's spiral)입니다.

Tables
함수는 값의 테이블로 표현될 수 있습니다. 만약 함수의 도메인이 유한이면, 함수는 이 방법에서 완전하게 지정될 수 있습니다. 예를 들어, 로 정의된 곱셈 함수 는 다음 익숙한 곱셈 테이블(multiplication table)에 의해 표현될 수 있습니다:


y x
|
1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1 | 1 | 2 | 3 | 4 | 5 |
| 2 | 2 | 4 | 6 | 8 | 10 |
| 3 | 3 | 6 | 9 | 12 | 15 |
| 4 | 4 | 8 | 12 | 16 | 20 |
| 5 | 5 | 10 | 15 | 20 | 25 |
다른 한편으로, 만약 함수의 도메인이 연속이면, 테이블은 도메인의 특정 값에서 함수의 값을 제공할 수 있습니다. 만약 사잇값이 요구되면, 보간(interpolation)은 함수의 값을 추정하기 위해 사용될 수 있습니다. 예를 들어, 사인 함수에 대해 테이블의 일부는 십진점 아래 6자리까지 반올림된 값을 갖는, 다음으로 제공될 수 있습니다:
| x | sin x |
|---|---|
| 1.289 | 0.960557 |
| 1.290 | 0.960835 |
| 1.291 | 0.961112 |
| 1.292 | 0.961387 |
| 1.293 | 0.961662 |
휴대용 계산기와 개인용 컴퓨터의 등장 전에, 그러한 테이블은 로그 및 삼각 함수와 같은 함수에 대해 종종 수집되고 출판되었습니다.
Bar chart
막대 차트는 그의 도메인이 유한 집합, 자연수 또는 정수인 함수를 나타내는 것에 대해 종종 사용됩니다. 이 경우에서, 도메인의 원소 x는 x-축의 구간(interval)에 의해 표현되고, 함수, f(x)의 해당하는 값은 그의 밑변이 x에 해당하는 구간이고 그의 높이가 f(x)인 직사각형(rectangle)에 의해 표현됩니다 (음수도 가능하며, 이 경우에서 막대는 x-축 아래로 확장됩니다).
General properties
이 섹션은 도메인 및 코도메인의 특정 속성에 독립적인, 함수의 일반적인 속성을 설명합니다.
Standard functions
자주 발생하는 많은 표준 함수가 있습니다:
- 모든 각 집합 X에 대해, 빈 집합(empty set)에서 X로의 빈 함수(empty function)로 불리는, 유일한 함수가 있습니다. 빈 함수의 존재는 이론의 일관성 및 많은 명제에서 빈 집합에 관련한 예외를 피하는 것에 대해 요구되는 관례입니다.
- 모든 각 집합 X와 모든 각 한원소 집합(singleton set) {s}에 대해, X에서 {s'}로의 유일한 함수가 있으며, 이것은 X의 모든 각 원소를 s로 매핑합니다. 이것은, 만약 X가 빈 집합이 아니면, 전사(surjection)입니다 (아래를 참조하십시오).
- 함수 가 주어지면, 그의 이미지(image) 위로의 f의 정식 전사가 존재하며, X에서, x를 f(x)로 매핑하는, f(X)로의 함수입니다.
- 집합 X의 모든 각 부분-집합(subset) A에 대해, A에서 Y 안으로 포함 맵(inclusion map)은 X의 모든 각 원소를 자체로 매핑하는, 단사입니다 (아래를 참조하십시오).
- 집합 X 위의 항등 함수(identity function)는, 로써 종종 나타내며, X에서 자체 안으로 포함입니다.


Function composition
g의 도메인이 f의 코도메인인 것을 만족하는, 두 함수 및 가 주어지면, 그들의 합성(composition)은 다음에 의해 정의된 함수 입니다:



즉, 의 값은 먼저 y =f(x)를 얻기 위해서 x에 의해 f를 적용하고 그런-다음 g(y) = g(f(x))를 얻기 위해 결과 y를 g에 적용함으로써 구해집니다. 표기법에서, 처음 적용되는 함수는 항상 오른쪽에 쓰입니다.

합성 는 만약 첫 번째 함수의 코도메인이 두 번째 함수의 도메인이면 오직 정의되는 함수에 대한 연산(operation)입니다. 비록 와 둘 다가 이들 조건을 만족시킬 때일지라도, 합성은 필연적으로 교환적(commutative)인 것은 아닙니다. 즉, 함수 와 가 같을 필요는 없지만, 같은 인수에 대해 다른 값을 배달할 수 있습니다. 예를 들어, f(x) = x2 및 g(x) = x + 1로 놓으면, 및 는 단지 에 대해 일치합니다.




함수 합성은, 만약 및 의 하나가 정의되면, 나머지 하나가 역시 정의되고, 그들은 같은 것인 의미에서 결합적(associative)입니다. 따라서, 우리는 다음을 씁니다:



항등 함수(identity function) 및 는 각각 X에서 Y로의 함수에 대해 오른쪽 항등원(right identity)과 왼쪽 항등원(left identity)입니다. 즉, 만약 f가 도메인 X, 및 코도메인 Y를 갖는 함수이면, 를 가집니다.


-
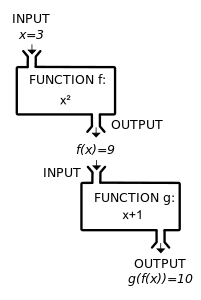 A composite function g(f(x)) can be visualized as the combination of two "machines".
A composite function g(f(x)) can be visualized as the combination of two "machines". -
 A simple example of a function composition
A simple example of a function composition -
 Another composition. In this example, (g ∘ f )(c) = #.
Another composition. In this example, (g ∘ f )(c) = #.



Image and preimage
로 놓습니다. 도메인 X의 원소 x의 f에 의한 이미지는 f(x)입니다. 만약 A가 X의 임의의 부분-집합이면, f(A)로 표기되는, f에 의한 A의 이미지는 A의 원소의 모든 이미지로 구성되는 코도메인 Y의 부분-집합입니다, 즉,

f의 이미지는 전체 도메인의 이미지, 즉 f(X)입니다. 그것은, 비록 그 용어가 코도메인에 대해 역시 참조될지라도, f의 치역(range)으로 역시 불립니다.[18]
다른 한편으로, 코도메인 Y의 부분-집합 B의 f에 의한 역 이미지(inverse image 또는 이전-이미지(preimage)는, 그의 이미지가 B에 속하는 X의 모든 원소로 구성되는 도메인 X의 부분-집합입니다. 그것은 로 나타냅니다. 즉


예를 들어, 제곱 함수(square function) 아래의 {4, 9}의 이전-이미지는 집합 {−3,−2,2,3}입니다.
함수의 정의에 의해, 도메인의 하나의 원소 x의 이미지는 코도메인의 항상 단일 원소입니다. 어쨌든, 로 나타내는, 단일 원소 y의 역이미지는 빈(empty) 것 또는 원소의 임의의 숫자를 포함할 수 있습니다. 예를 들어, 만약 f가 정수에서 그들 자신으로의 함수이고, 모든 각 정수를 0으로 맵핑하면, 입니다.


만약 가 함수이고, A와 B는 X의 부분-집합이고, C와 D는 Y의 부분-집합이면, 우리는 다음 속성을 가집니다:






코도메인의 원소 y의 f에 의한 역이미지는, 일부 문맥에서, f 아래의 y의 올(fiber)로 때때로 불립니다.
만약 함수 f가 역을 가지면 (아래를 참조하십시오), 이 역은 로 나타냅니다. 이런 경우에서 는 에 의한 이미지 또는 C의 f에 의한 역이미지를 나타낼 수 있습니다. 이것은 문제가 되지 않는데, 왜냐하면 이들 집합은 같기 때문입니다. 표기법 및 는, 와 같은, 원소로 일부 부분-집합을 포함하는 집합의 경우에서 모호할 수 있습니다. 이런 경우에서, 약간의 주의는, 예를 들어, 부분-집합의 이미지와 역이미지에 대해 대괄호 를 사용하고, 원소의 이미지와 역이미지에 대해 일반 괄호를 사용하는 것이, 요구될 수 있습니다.




![{\displaystyle f[A],f^{-1}[C]}](https://dawoum.duckdns.org/api/rest_v1/media/math/render/svg/6d728b72b3681c1a33529ac867bc49952dc812a4)
Injective, surjective and bijective functions
를 함수로 놓습니다.
함수 f는, 만약 X의 임의의 두 다른 원소 a와 b에 대해 f(a) ≠ f(b)이면, 단사(injective) (또는 일대일(one-to-one), 또는 단사 함수(injection))입니다. 동등하게, f는, 만약 임의의 에 대해, 역이미지 가 많아야 하나의 원소로 구성되면, 단사입니다. 빈 집합은 항상 단사입니다. 만약 X가 빈 집합(공집합)이 아니면, 및, 만약, 보통처럼, 체르멜로–프렝켈 집합 이론(Zermelo–Fraenkel set theory)이 가정되면, f가 단사인 것과 를 만족하는 함수 가 존재하는 것, 즉, f가 왼쪽 역함수(left inverse)를 가지는 것은 필요충분 조건입니다. 만약 f가 단사이면, g를 정의하는 것에 대해, 우리는 X에서 원소 를 선택하고 (이것은 X가 비-빈 것으로 가정되기 때문에 존재합니다),[note 6] 우리는, 만약 이면, 및 만약 이면, 에 의해 정의합니다.






함수 f는, 만약 치역이 코도메인과 같으면, 즉, 만약 f(X) = Y이면, 전사(surjective) (또는 위로의(onto), 또는 전사 함수(surjection))입니다. 달리 말해서, 모든 각 의 역이미지 는 비-빈입니다. 만약, 보통처럼, 선택의 공리가 가정되면, f가 전사인 것과 를 만족하는 함수 가 존재하는 것, 즉, 만약 f는 오른쪽 역함수(right inverse)를 가지는 것은 필요충분 조건입니다. 선택의 공리가 요구되는데, 왜냐하면, 만약 f가 전사이면, 우리는 에 의해 g를 정의하며, 여기서 는 의 임의로 선택된(arbitratily chosen) 원소입니다.

함수 f는, 만약 그것이 단사와 전사 둘 다이면, 전단사(bijective) (또는 전단사 함수(bijection) 또는 일대일 대응(one-to-one correspondence))입니다. 즉, f는, 만약 임의의 에 대해, 역이미지 가 정확히 하나의 원소를 포함하면, 전단사입니다. 함수 f가 전단사인 것과 그것이 역함수(inverse function)를 허용하는 것, 즉, 및 를 만족하는 함수 인 것은 필요충분 조건입니다. (전사의 경우와는 달리, 이것은 선택의 공리를 요구하지 않습니다.)
모든 각 함수 는 단사에 뒤이어서 전사의 i ∘ s 합성으로 인수화(factorized)될 수 있으며, 여기서 s는 f(X) 위로의 X의 정식 전사이고, i는 Y로의 f(X)의 정식 단사입니다. 이것은 f의 정식 인수분해(canonical factorization)입니다.
"일-대-일(one-to-one)" 및 "위로의(onto)"는 오래된 영어 문헌에서 보다 공통적이었던 용어입니다; "단사(injective)", "전사(surjective)", 및 "전단사(bijective)"는 부르바키 그룹(Bourbaki group)에 의해 20세기의 이분기에서 프랑스 단어로써 원래 도입되었고, 영어로 수입되었습니다. 주의해야 할 단어로, "일-대-일 함수"는 단사 함수의 하나이고, 반면에 "일-대-일 대응"은 전단사 함수를 참조합니다. 역시, 명제 "f는 X에서 Y 위로의(onto) 매핑한다"는 것은 "f는 X에서 B 안으로(into) 매핑한다"는 것은 다르며, 전자는 f는 전사를 의미하며, 반면에 후자는 매핑 f의 본성에 대하여 어떤 주장을 하지 않습니다. 복잡한 추론에서, 한 글자 차이는 쉽게 놓칠 수 있습니다. 이런 오래된 용어의 혼란스러운 본성에 기인하여, 이들 용어는 브로바키 용어와 관련하여 인기가 떨어져 왔으며, 이것은 보다 대칭적이라는 이점(advantage)을 역시 가집니다.
Restriction and extension
만약 가 함수이고, S가 X의 부분-집합이면, 로 표시되는, S에 대한 f의 제한(restriction)은 S에서 Y로의 함수이며, S에서 모든 x에 대해 다음에 의해 정의됩니다:

- .

제한은 부분 역 함수를 정의하기 위해 사용될 수 있습니다: 만약 가 단사를 만족하는 함수 f의 부분-집합 S가 있으면, 그의 이미지 위로의 의 정식 전사는 전단사이고, 따라서 에서 S로의 역함수를 가집니다. 한 응용은 역 삼각 함수(inverse trigonometric function)의 정의입니다. 예를 들어, 코사인 함수(cosine function)는 구간(interval) (–0, π)로 제한될 때, 단사입니다; 이 제한의 이미지는 구간 (–1, 1)이고, 따라서 제한은 (–1, 1)에서 (–0, π)로의 역함수를 가지며, 이것은 아크코사인(arccosine)으로 불리고 arccos으로 나타냅니다.


함수 제한은 함께 "접착(gluing)" 함수에 대해 역시 사용될 수 있습니다. 를 부분-집합의 합집합(union)으로 X의 분해로 놓고, 함수 는, 인덱스의 각 쌍에 대해, 와 에서 로의 제한이 같음을 만족하는, 각 위에 정의되는 것을 가정합니다. 그런-다음 이것이, 모든 i에 대해 를 만족하는 유일한 함수 를 정의합니다. 이것이 다양체(manifold) 위의 함수가 정의되는 방법입니다.







함수 f의 확장(extension)은 f가 g의 제한을 만족하는 함수 g입니다. 이 개념의 전형적인 사용은, 그의 도메인이 복소 평면(complex plane)의 작은 부분인 함수에서 그의 도메인이 거의 모든 복소 평면인 함수로의 확장을 허용하는, 해석적 연속(analytic continuation)의 프로세스입니다.
여기서 실수 직선(real line)의 호모그래피(homography)을 연구할 때 직면하게 되는 함수 확장의 또 다른 고전적인 예제가 있습니다. 호모그래피(homography)는 ad – bc ≠ 0를 만족하는 함수 입니다. 그의 도메인은 와 다른 모든 실수(real)의 집합이고, 그의 이미지는 }와 다른 모든 실수의 집합입니다. 만약 우리가 실수 직선을 ∞를 포함함으로써 투영적으로 확장된 실수 직선(projectively extended real line)으로 확장하면, 우리는 h를 와 를 설정함으로써 확장된 실수 직선에서 자체로의 전단사로 확장할 수 있습니다.





Multivariate function



다변수 함수(multivariate function), 또는 여러 변수의 함수(function of several variables)는 여러 인수에 의존하는 함수입니다. 그러한 함수는 공통적으로 마주칩니다. 예를 들어, 도로 위의 자동차의 위치는 시간과 그의 속력의 함수입니다.
보다 공식적으로, n 변수의 함수는 그의 도메인이 n-튜플(n-tuples)의 집합인 함수입니다. 예를 들어, 정수의 곱셈은 두 변수의 함수, 또는 이변수 함수(bivariate function)이며, 그의 도메인은 정수(integer)의 모든 쌍 (2-튜플)의 집합이고, 그의 코도메인은 정수의 집합입니다. 같은 것은 모든 각 이항 연산(binary operation)에 대해 참입니다. 보다 일반적으로, 모든 각 수학적 연산(mathematical operation)은 곱셈의 함수로 정의됩니다.
n 집합 의 데카르트 곱(Cartesian product) 은 을 갖는 모든 각 i에 대해 를 만족하는 모든 n-튜플 의 집합입니다. 그러므로, n 변수의 집합은 다음 함수입니다:






여기서 도메인 U는 다음 형식을 가집니다:

함수 표기법이 사용될 때, 우리는 보통 튜플을 감싸는 괄호는 생략되며, instead of 으로 씁니다.


모든 가 실수(real number)의 집합 과 같은 경우에서, 우리는 여러 실수 변수의 함수(function of several real variables)를 가집니다. 만약 가 복소수의 집합 와 같음면, 우리는 여러 복소 변수의 함수(function of several complex variables)를 가집니다.

그의 도메인이 집합의 곱인 함수를 역시 고려하는 것이 공통적입니다. 예를 들어, 유클리드 나눗셈(Euclidean division)은 b ≠ 0를 갖는 정수의 모든 각 쌍 (a, b)를 몫과 나머지로 불리는 정수의 쌍에 매핑합니다.

코도메인은 역시 벡터 공간(vector space)일 수 있습니다. 이 경우에서, 우리는 벡터-값 함수(vector-valued function)로 말합니다. 만약 도메인이 유클리드 공간(Euclidean space), 또는 보다 일반적으로 매니폴드(manifold)에 포함되면, 벡터-값 함수는 종종 벡터 필드(vector field)로 불립니다.
In calculus
17세기에서 시작된, 함수 아이디어는 새로운 무한소 미적분(infinitesimal calculus)에 기초가 되었습니다 (함수 개념의 역사(History of the function concept)를 참조하십시오). 당시에서, 오직 실수 변수의 실수-값(real-valued) 함수가 고려되었었고, 모든 함수는 매끄러운(smooth) 것으로 가정했습니다. 그러나, 그 정의는 곧 여러 변수의 함수 및 복소 변수의 함수(functions of a complex variable)로 확장되었습니다. 19세기 후반에서, 함수의 수학적으로 엄격한 정의가 도입되었었고, 임의의 도메인과 코도메인을 가진 함수가 정의되었습니다.
함수는 이제 수학의 모든 분야에 걸쳐 사용됩니다. 입문 미적분학(calculus)에서, 단어 함수가 자격없이 사용될 때, 그것은 단일 실수 변수의 실수-값 함수를 의미합니다. 함수의 보다 일반적인 정의는 보통 STEM 전공을 가진 2학년 또는 3학년 대학생들에게 도입되고, 그들의 남은 학년에서 그들은 실수 해석학(real analysis) 및 복소 해석학(complex analysis)과 같은 과정에서 더 크고 보다 엄격한 환경에서 미적분학에 도입됩니다.
Real function



실수 함수(real function)은 실수 변수(real variable)의 실수-값(real-valued) 함수, 즉, 그의 도메인이 실수(real number)의 필드이고 그의 코도메인이 구간(interval)을 포함하는 실수의 집합인 함수입니다. 이 섹션에서, 이들 함수는 간단히 함수로 불립니다.
수학과 그의 응용에서 가장 공통적으로 고려되는 함수는 어떤 규칙성을 가지며, 즉 그들은 연속(continuous), 미분-가능(differentiable), 및 심지어 해석적(analytic)입니다. 이 규칙성은 이들 함수가 그들의 그래프(graphs)에 의해 시각화될 수 있음을 보증합니다. 이 섹션에서, 모든 함수는 일부 구간에서 미분-가능입니다.
함수는 점-별 연산(pointwise operation)을 수행하며, 즉 만약 f와 g가 함수이면, 그들의 합, 차이 및 곱은 다음에 의해 정의된 함수입니다:

결과 함수의 도메인은 f와 g의 도메인의 교집합(intersection)입니다. 두 함수의 몫은 다음에 의해 비슷하게 정의됩니다:

그러나 결과 함수의 도메인은 f와 g의 도메인의 교집합으로부터 g의 영(zeros)을 제거함으로써 얻습니다.
다항 함수(polynomial function)는 다항식(polynomial)에 의해 정의되고, 그들의 도메인은 실수의 전체 집합입니다. 그들은 상수 함수(constant function), 선형 함수(linear function) 및 이차 함수(quadratic function)를 포함합니다. 유리 함수(Rational function)는 두 다항 함수의 몫이고, 그들의 도메인은 영에 의한 나눗셈(division by zero)을 피하기 위해 제거된 그들의 유한 숫자를 갖는 실수입니다. 가장-간단한 유리 함수는 함수는 이며, 그의 그래프는 쌍곡선(hyperbola)이고, 그의 도메인은 0을 제외한 전체 실수 직선(real line)입니다.

실수 미분-가능 함수의 도함수(derivative)는 실수 함수입니다. 연속 실수 함수의 역도함수(antiderivative)는 원래 함수가 연속인 것에서 임의의 열린 구간(open interval)에서 미분-가능한 실수 함수입니다. 예를 들어, 함수 는 연속이고, 심지어 양의 실수 위에 미분-가능입니다. 따라서 x = 1에 대해 값 영을 취하는 하나의 역도함수는 자연 로그(natural logarithm)로 불리는 미분-가능한 함수입니다.
실수 함수 f는, 만약 의 부호가 구간에서 x와 y의 선택에 의존하지 않으면, 구간에서 단조적(monotonic)입니다. 만약 함수가 구간에서 미분-가능이면, 그것은, 만약 도함수의 부호가 구간에서 상수이면 단조적입니다. 만약 실수 함수 f가 구간 I에서 단조적이면, 그것은 역 함수(inverse function)를 가지며, 이것은 도메인 f(I)와 이미지 I를 갖는 실수 함수입니다. 이것이 역 삼각 함수(inverse trigonometric functions)가 삼각 함수(trigonometric functions)의 관점에서 정의되는 방법이며, 여기서 삼각 함수는 단조적입니다. 또 다른 예제: 자연 로그는 양의 실수 위에 단조적이고, 그이 이미지는 전체 실수 직선입니다; 그러므로 그것은 실수와 양의 실수 사이의 전단사(bijection)인 역 함수를 가집니다. 이것은 지수 함수(exponential function)의 역입니다.

많은 다른 실수 함수는 암시적 함수 정리(implicit function theorem) (역 함수는 특정 예제입니다) 또는 미분 방정식(differential equation)의 해로 정의됩니다. 예를 들어, 사인 및 코사인 함수는 다음을 만족하는:

다음 선형 미분 방정식(linear differential equation)의 해입니다:
- .

Vector-valued function
함수의 코-도메인의 원소가 벡터(vectors)일 때, 함수는 벡터-값 함수로 말합니다. 이들 함수는 응용, 예를 들어 물리적 속성 모델링에서 유용합니다. 유체의 각 점에 그의 속도(velocity) 벡터를 연결하는 함수는 벡터-값 함수입니다.
일부 벡터-값 함수는 의 부분-집합 또는, 매니폴드(manifolds)와 같은, 과 비슷한 기하학적 또는 토폴로지적(topological) 속성을 공유하는 다른 공간 위에 정의됩니다. 이들 벡터-값 함수는 이름 벡터 필드로 제공됩니다.
Function space
수학적 해석학(mathematical analysis), 및 보다 구체적으로 함수형 해석학(functional analysis)에서, 함수 공간(function space)은 스칼라-값(scalar-valued) 또는 벡터-값 함수(vector-valued function)의 집합이며, 이것은 특정 속성을 공유하고 토폴로지적 벡터 공간(topological vector space)을 형성합니다. 예를 들어, 컴팩트 지원(compact support) (즉, 그들은 일부 컴팩트 집합(compact set) 외부에 0입니다)를 가진 실수 매끄러운 함수(smooth function)는 분포(distributions)의 이론을 기반으로 하는 것에서 함수 공간을 형성합니다.
함수 공간은 함수의 속성을 연구하는 것에 대해 대수적 및 토폴로지적(topological) 속성의 사용을 허용함으로써, 고급 수학적 해석학에서 근본적인 역할을 합니다. 예를 들어, 보통(ordinary) 또는 부분 미분 방정식(partial differential equation)의 해에 대한 존재 및 고유성의 모든 이론은 함수 공간의 연구의 결과입니다.
Multi-valued functions


실수 또는 복소 변수의 함수를 지정하는 여러 방법은 한 점에서 또는 한 점의 이웃(neighbourhood)에서 함수의 지역적 정의로부터 시작하고, 그런-다음 연속성에 의해 함수를 훨씬 더 큰 도메인으로 확장합니다. 자주, 점 으로 시작하여, 함수에 대해 여러 가능한 시작하는 값이 있습니다.

예를 들어, 제곱 근(square root)을 제곱 함수의 역 함수로 정의하는 것에서, 임의의 양의 실수 에 대해, 제곱근의 값에 대해 두 선책이 있으며, 그것의 하나는 양수이고 로 나타내고, 그것의 또 다른 하나는 음수이고 로 나타냅니다. 이들 선택은 비-음의 실수를 도메인으로 가지는 것, 비-음 또는 비-양의 실수를 이미지로 가지는 것 둘 다에서, 두 연속 함수를 정의합니다. 이들 함수의 그래프를 볼 때, 우리는, 함께, 그들이 단일 매끄러운 곡선(smooth curve)을 형성한다는 것을 알 수 있습니다. 그러므로 이들 두 제곱근 함수를 양의 x에 대해 두 값, 0에 대해 하나의 값을 가지고 음의 x에 대해 값이 없는 단일 함수로 여기는 것이 종종 유용합니다.


이전 예제에서, 하나의 선택, 양의 제곱근은 나머지 하나보다 더 자연스럽습니다. 이것은 일반적인 경우에서 그렇지 않습니다. 예를 들어, y를 의 근(root) x에 매핑하는 암시적 함수(implicit function)를 생각해 보십시오 (오른쪽 그림 참조하십시오). y = 0에 대해, 우리는 x에 대해 , 또는 중 하나를 선택할 수 있습니다. 암시적 함수 정리(implicit function theorem)에 의해, 각 선택은 함수를 정의합니다; 첫 번째 것에 대해, (최대) 도메인은 구간 [–2, 2]이고 이미지는 [–1, 1]입니다; 두 번째 것에 대해, 도메인은 [–2, ∞)이고 이미지는 [1, ∞)입니다; 마지막 것에 대해, 도메인이 (–∞, 2]이고 이미지는 (–∞, –1]입니다. 세 그래프가 함께 매끄러운 곡선을 형성하고, 하나의 선택을 선호할 이유가 없으므로, 이들 세 함수는 –2 < y < 2에 대해 세 값을 가지고, y ≤ –2 및 y ≥ –2에 대해 오직 하나의 값을 갖는 y의 단일 다중-값 함수로 종종 여겨집니다.



다중-값 함수 개념의 유용성은 복소 함수, 전형적으로 해석적 함수(analytic function)를 고려할 때 더 명확합니다. 복소 함수가 해석적 연속(analytic continuation)에 의해 확장될 수 있는 것에서 도메인은 일반적으로 전체 복소 평면(complex plane)으로 거의 구성됩니다. 어쨌든, 두 다른 경로를 통해 도메인을 확장할 때, 우리는 종종 다른 값을 얻습니다. 예를 들어, 양의 허수 부분을 갖는 복소수의 경로를 따라 제곱근 함수의 도메인을 확장할 때, 우리는 –1의 제곱근에 대해 i를 얻습니다; 반면에, 음의 허수 부분을 갖는 복소수를 통해 확장할 때, 우리는 –i를 얻습니다. 문제를 해결하는 방법은 일반적으로 두 방법이 있습니다. 우리는 가지 자름(branch cut)으로 불리는 일부 곡선을 따라 연속적(continuous)이지 않은 함수를 정의할 수 있습니다. 그러한 함수는 함수의 주요 값(principal value)으로 불립니다. 다른 방법은 하나가 다중-값 함수를 가지는 것으로 고려하는 것이며, 이것은 고립된 특이점을 제외한 모든 곳에서 해석적이지만, 그의 값은, 만약 하나가 특이점 주위에서 닫힌 루프를 따라가면, "점프"할 수 있습니다. 이 점프는 모노드로미(monodromy)로 불립니다.
In the foundations of mathematics and set theory
이 기사에서 제공되는 함수의 정의는 집합(set)의 개념을 요구하는데, 왜냐하면 함수의 도메인과 코도메인은 반드시 집합이기 때문입니다. 이것은 보통의 수학에서 문제가 아닌데, 왜냐하면 그것은 일반적으로 그의 도메인과 코도메인이 집합인 함수를 오직 고려하는 것이 어렵지 않기 때문입니다. 어쨌든, 보다 일반적인 함수를 고려하는 것이 때때로 유용합니다.
예를 들어, 한원소 집합(singleton set)은 함수 로 여길 수 있습니다. 그의 도메인은 모든 집합을 포함할 것이고, 그러므로 집합이 아닐 것입니다. 보통 수학에서, 우리는 도메인을 지정함으로써 이런 종류의 문제를 피하며, 이것은 우리가 많은 한원소 함수를 가지는 것을 의미합니다. 어쨌든, 수학의 기초를 확립할 때, 우리는 도메인, 코도메인, 또는 둘 다 지정되지 않은 함수를 사용해야 할 수 있고, 일부 저자, 종종 논리학자는 이들 약하게 지정된 함수에 대해 정확한 정의를 제공합니다.[19]

이들 일반화된 함수는 수학의 기초(foundations of mathematics)의 공식화의 개발에서 결정적일 수 있습니다. 예를 들어, 폰 노이만-베르나이스-괴델 집합 이론(Von Neumann–Bernays–Gödel set theory)은 집합 이론의 확장이며 이것에서 모든 집합의 모음은 클래스(class)입니다. 이 이론은 대체 공리(replacement axiom)를 포함하며, 이것은 "만약 X가 집합이고, F가 함수이면, F[X]가 집합입니다"로 해석될 수 있을 것입니다.
In computer science
컴퓨터 프로그래밍(computer programming)에서, 함수(function)는, 일반적으로, 컴퓨터 프로그램(computer program)의 일부이며, 이것은 함수의 추상 개념을 구현(implements)합니다. 즉, 그것은 각 입력에 대해 출력을 생성하는 프로그램 단위입니다. 어쨌든, 많은 프로그래밍 언어(programming language)에서, 모든 각 서브루틴(subroutine)은, 심지어 출력이 없을 때, 및 기능성이 단순히 컴퓨터 메모리(computer memory)에서 일부 데이터를 수정하는 것으로 구성될 때, 함수를 호출합니다.
함수형 프로그래밍(Functional programming)은 수학 함수처럼 작동하는 서브루틴을 오직 사용하여 프로그램을 빌딩을 구성하는 프로그래밍 패러다임(programming paradigm)입니다. 예를 들어, if_then_else는 세 함수를 인수로 취하는 함수이고, 첫 번째 함수의 결과 (참 또는 거짓)에 따라, 두 번째 또는 세 번째 함수의 결과를 반환합니다. 함수형 프로그래밍의 중요한 장점은 프로그램 증명(program proof)을 더 쉽게 만드는 것인데, 왜냐하면 잘 다져진 이론, 람다 계산법(lambda calculus)을 기초로 하기 때문입니다 (아래를 참조하십시오).
컴퓨터-언어 용어를 제외하고, "함수"는 컴퓨터 과학(computer science)에서 보통 수학적 의미를 가집니다. 이 분야에서, 주요 관심의 속성은 함수의 계산-가능성(computability)입니다. 이 개념, 및 관련된 알고리듬(algorithm)의 개념에 대한 정확한 의미를 제공하는 것에 대해, 여러 계산의 모델(models of computation)이 도입되어 왔으며, 이전 모델은 일반적인 재귀 함수(general recursive function), 람다 계산법(lambda calculus) 및 튜링 기계(Turing machine)입니다. 계산-가능성 이론(computability theory)의 기본 정리는 이들 세 계산 모델이 계산-가능한 함수의 같은 집합을 정의하고 제안되어 온 다른 모든 계산의 모델은 계산-가능한 함수의 같은 집합 또는 더 작은 것을 정의한다는 것입니다. 처치-튜링 논제(Church-Turing thesis)는 계산-가능한 함수의 철학적으로 수용-가능한 모든 각 정의가 같은 함수를 역시 정의한다는 주장입니다.
일반적인 재귀 함수는 정수에서 정수로의 부분 함수(partial function)이며 다음으로부터 정의될 수 있습니다:
- 상수 함수(constant function),
- 다음수(successor), 및
- 투영(projection) 함수, 이것들은 다음 연산자를 통한 것입니다:
- 합성(composition),
- 원시 재귀(primitive recursion), 및
- 최소화(minimization).
비록 정수에서 정수로의 함수에 대해 오직 정의될지라도, 그들은 다음 속성의 결과로 임의의 계산-가능한 함수를 모델링할 수 있습니다:
- 계산은 기호의 유한 수열의 조작입니다 (숫자의 자릿수, 공식, ...),
- 기호의 모든 각 수열은 비트(bit)의 수열로 코드될 수 있습니다,
- 비트 수열은 정수의 이진 표현(binary representation)으로 해석될 수 있습니다.
람다 계산법(Lambda calculus)은 집합 이론(set theory)의 사용없이 계산-가능한 함수를 정의하는 이론이고, 함수형 프로그래밍의 이론적 배경입니다. 그것은 변수, 함수 정의 (λ-항), 또는 항에 대한 함수의 응용 중의 하나인 항을 구성합니다. 항은 일부 규칙, (α-등가, β-감소, 및 η-변환)을 통해 조작되며, 이것은 이론의 공리(axiom)이고 계산의 규칙으로 해석될 수 있습니다.
그의 원래 형식에서, 람다 계산법은 함수의 도메인 및 코도메인의 개념을 포함하지 않습니다. 대락 말해서, 그들은 유형화된 람다 계산법(typed lambda calculus)에서 유형의 이름 아래의 이론에서 도입되어 왔습니다. 유형화된 람다 계산법의 대부분 종류는 비-유형화된 람다 계산법보다 더 적은 함수를 정의할 수 있습니다.
See also
Subpages
Generalizations
Related topics
Notes
- ^ The words map, mapping, transformation, correspondence, and operator are often used synonymously. Halmos 1970, p. 30.
- ^ This definition of "graph" refers to a set of pairs of objects. Graphs, in the sense of diagrams, are most applicable to functions from the real numbers to themselves. All functions can be described by sets of pairs but it may not be practical to construct a diagram for functions between other sets (such as sets of matrices).
- ^ The sets X, Y are parts of data defining a function; i.e., a function is a set of ordered pairs with , together with the sets X, Y, such that for each , there is a unique with in the set.
- ^ This follows from the axiom of extensionality, which says two sets are the same if and only if they have the same members. Some authors drop codomain from a definition of a function, and in that definition, the notion of equality has to be handled with care; see, for example, "When do two functions become equal?". Stack Exchange. August 19, 2015.
- ^ Here "elementary" has not exactly its common sense: although most functions that are encountered in elementary courses of mathematics are elementary in this sense, some elementary functions are not elementary for the common sense, for example, those that involve roots of polynomials of high degree.
- ^ The axiom of choice is not needed here, as the choice is done in a single set.

References
- ^ MacLane, Saunders; Birkhoff, Garrett (1967). Algebra (First ed.). New York: Macmillan. pp. 1–13.
- ^ Spivak 2008, p. 39.
- ^ Hamilton, A. G. (1982). Numbers, sets, and axioms: the apparatus of mathematics. Cambridge University Press. p. 83. ISBN 978-0-521-24509-8.
function is a relation.
- ^ Apostol 1981, p. 35.
- ^ Kaplan 1972, p. 25.
- ^ Gunther Schmidt( 2011) Relational Mathematics, Encyclopedia of Mathematics and its Applications, vol. 132, sect 5.1 Functions, pp. 49–60, Cambridge University Press ISBN 978-0-521-76268-7 CUP blurb for Relational Mathematics
- ^ Halmos, Naive Set Theory, 1968, sect.9 ("Families")
- ^ Ron Larson, Bruce H. Edwards (2010), Calculus of a Single Variable, Cengage Learning, p. 19, ISBN 978-0-538-73552-0
- ^ Weisstein, Eric W. "Map". mathworld.wolfram.com. Retrieved 2019-06-12.
- ^ Lang, Serge (1971), Linear Algebra (2nd ed.), Addison-Wesley, p. 83
- ^ T. M. Apostol (1981). Mathematical Analysis. Addison-Wesley. p. 35.
- ^ a b "function in nLab". ncatlab.org. Retrieved 2019-06-12.
- ^ "homomorphism in nLab". ncatlab.org. Retrieved 2019-06-12.
- ^ "morphism". nLab. Retrieved 2019-06-12.
- ^ Weisstein, Eric W. "Morphism". mathworld.wolfram.com. Retrieved 2019-06-12.
- ^ T. M. Apostol (1981). Mathematical Analysis. Addison-Wesley. p. 35.
- ^ Lang, Serge (1971), Linear Algebra (2nd ed.), Addison-Wesley, p. 83
- ^ Quantities and Units - Part 2: Mathematical signs and symbols to be used in the natural sciences and technology, p. 15. ISO 80000-2 (ISO/IEC 2009-12-01)
- ^ Gödel 1940, p. 16; Jech 2003, p. 11; Cunningham 2016, p. 57
Sources
- Bartle, Robert (1967). The Elements of Real Analysis. John Wiley & Sons.
- Bloch, Ethan D. (2011). Proofs and Fundamentals: A First Course in Abstract Mathematics. Springer. ISBN 978-1-4419-7126-5.
- Cunningham, Daniel W. (2016). Set theory: A First Course. Cambridge University Press. ISBN 978-1-107-12032-7.
- Gödel, Kurt (1940). The Consistency of the Continuum Hypothesis. Princeton University Press. ISBN 978-0-691-07927-1.
- Halmos, Paul R. (1970). Naive Set Theory. Springer-Verlag. ISBN 978-0-387-90092-6.
- Jech, Thomas (2003). Set theory (Third Millennium ed.). Springer-Verlag. ISBN 978-3-540-44085-7.
- Spivak, Michael (2008). Calculus (4th ed.). Publish or Perish. ISBN 978-0-914098-91-1.
Further reading
- Anton, Howard (1980). Calculus with Analytical Geometry. Wiley. ISBN 978-0-471-03248-9.
- Bartle, Robert G. (1976). The Elements of Real Analysis (2nd ed.). Wiley. ISBN 978-0-471-05464-1.
- Dubinsky, Ed; Harel, Guershon (1992). The Concept of Function: Aspects of Epistemology and Pedagogy. Mathematical Association of America. ISBN 978-0-88385-081-7.
- Hammack, Richard (2009). "12. Functions" (PDF). Book of Proof. Virginia Commonwealth University. Retrieved 2012-08-01.
- Husch, Lawrence S. (2001). Visual Calculus. University of Tennessee. Retrieved 2007-09-27.
- Katz, Robert (1964). Axiomatic Analysis. D. C. Heath and Company.
- Kleiner, Israel (1989). "Evolution of the Function Concept: A Brief Survey". The College Mathematics Journal. 20 (4): 282–300. CiteSeerX 10.1.1.113.6352. doi:10.2307/2686848. JSTOR 2686848.
- Lützen, Jesper (2003). "Between rigor and applications: Developments in the concept of function in mathematical analysis". In Porter, Roy (ed.). The Cambridge History of Science: The modern physical and mathematical sciences. Cambridge University Press. ISBN 978-0-521-57199-9. An approachable and diverting historical presentation.
- Malik, M. A. (1980). "Historical and pedagogical aspects of the definition of function". International Journal of Mathematical Education in Science and Technology. 11 (4): 489–492. doi:10.1080/0020739800110404.
- Reichenbach, Hans (1947) Elements of Symbolic Logic, Dover Publishing Inc., New York, ISBN 0-486-24004-5.
- Ruthing, D. (1984). "Some definitions of the concept of function from Bernoulli, Joh. to Bourbaki, N.". Mathematical Intelligencer. 6 (4): 72–77.
- Thomas, George B.; Finney, Ross L. (1995). Calculus and Analytic Geometry (9th ed.). Addison-Wesley. ISBN 978-0-201-53174-9.
External links
- "Function", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Weisstein, Eric W. "Function". MathWorld.
- The Wolfram Functions Site gives formulae and visualizations of many mathematical functions.
- NIST Digital Library of Mathematical Functions